
Paulo Sasaki & Consultores Associados
Artificial Intelligence, Deep Learning, Big Data, Ciber Security
Desde 1995
blog: paulosasakiblog.wordpress.com
CV´s
Análise - Modelagem
= ??


Os que iniciaram os estudos de modelagens de dados nos anos 80 (como eu), tiveram de enfrentar uma fase árdua, durante a qual ferramentas já prontas não estavam disponíveis. E lidaram com cálculos diversos, ou em calculadoras, ou em grandes mainframes (o que foi o meu caso, por trabalhar na IBM), manualmente.
Uma das modelagens mais conhecidas é a correlacional, baseada no Coeficiênte de Correlação de Pearson, no qual se divide a covariância de duas variáveis pelo produto de seus desvios-padrão:
Por isso, ao final da decada de 90 e início da próxima, com o advento dos computadores pessoais e ferramentas estatísticas e matemáticas disponíveis via internet, decidi, imediatamente, incorporar tal instrumental aos meus estudos. Para isso, comecei com redes neurais da Alyuda(tm), e as únicas bases de dados de que dispunha (dados meteorológicos gerados pelas estações do INMEP).
Os dados continham informações como temperatura, velocidade e direção do vento, umidade relativa do ar, índice pluviométrico, assim como operacionais (como o nível de bateria da estação).
Para minha grande surpresa, minha primeira rede neural concluiu que quando a bateria da estação 83773 (Avaré - SP), ficava fraca, chovia mais na estação 83714 (Campos do Jordão - SP) !!!!!!!!!
Nesse momento, ficou claro que minha modelagem estava completamente errada, e minhas técnicas necessitavam (urgentemente), de revisões aprofundadas
Conteúdo
1 - O Armazem de Dados (DW) básico 2 - Conjuntos de Dados 3 - Análises X Modelagens X Dados 4 - Aferição de Resultados
O Armazem de Dados (DW) básico
Ross Kimball e Bill Inmon forneceram algumas das primeiras visões arquiteturais do que deveria ser um DW para modelagem dimensional, e as etapas para sua construção:


Em termos práticos, há pouca diferença entre ambas as implementações e, principalmente, em suas funcionalidades.
Há sempre os processos distintos de Extração, Transformação (normalizações, padronizações, aderência a conformidades), e carga de um Banco de Dados, central ou distribuído, ao qual se permite o acesso por ferramentas de modelagem.
Caso o projeto assim o exija e permita, subconjuntos desta(s) base(s), poderão ser criados, especificamente para uma área ou assunto (os chamados "DataMarts").
Conjuntos de Dados
Modelagens nunca são feitas em todo o "oceano" de dados disponível no DW. Cada uma exige um subconjunto dos mesmos, específicos para o tipo de estudo desejado, conhecido como "dataset".
A seleção dos dados que comporão o subconjunto é vital para seus resultados (ver o exemplo ao topo), uma vez que as ferramentas de estudo, por suas características estatísticas e matemáticas, produzirão "algum" resultado, não importa a bobagem que o mesmo represente.
Em alguns casos, pode-se utilizar os resultados já totalizados de KPI's específicos, indicadores sob os mesmos, ou qualquer combinação que seja apropriada.
O maior cuidado a se tomar na criação de datasets, é que, de certa forma, eles já determinam a análise ou modelagem a ser criada. Ou, mais claramente, os datasets devem ser criados tendo-se em mente seu objetivo. Redes Neurais, por exemplo, saturam a partir de (aprox.) 10 / 100 (ou 10 campos com 100 registros), enquanto que séries temporais precisam de mais dados, para distinguir causalidades, correlacionamentos e coincidências.

Análises X Modelagens X Dados


Gosto da análogia entre "análise" e "correlacionamento", bem como "modelagem" com "experimental". E entre seus sinônimos, gosto particularmente de "estudo" e "revisão", para análise, e "ajuste" para modelagem.
Na análise, olhamos "para trás", buscando relacionamentos entre dados invariantes (históricos, fixos ou, na terminologia de data analytics, independentes).
Já na modelagem, mudamos dados em uma ou mais equações que componham o modelo (tornando-os variáveis ou dependentes), de forma a prever mudanças.
São funções diferentes, e que servem à propósitos distintos. Por exemplo, se queremos calcular quando um determinado recurso se esgotará, uma análise e projeção históricas podem resolver. Ao passo que se quisermos prever o impacto de determinadas mudanças no curso normal de uma linha histórica, a modelagem via redes neurais pode ser a melhor escolha.
Tipos de Dados:
Em última instância, distingo os dados de entrada em 2 tipos: séries temporais e agrupamentos ("clusters").
Séries Temporais
Digamos que uma empresa de armazenamento tenha 10 galpões, cada um com suas características de ferramental, facilidades logísticas e espaço. Podemos utilizar como série temporal o espaço (em volume), utilizado para cada um deles, e projetar o ponto em que estarão esgotados. Ou podemos resumir (soma ponderada), de todos eles em um único KPI ("utilização de espaço"), com a mesma finalidade, em uma visão mais resumida ou corporativa. O ideal seria o uso das duas, pois na visão sumarizada (KPI), há uma indicação de sobre-utilização que ainda permite a distribuição com recursos próprios na empresa. De posse dela, pode-se fazer um aprofundamento ("drill-down"), nos recursos unitários, movendo, por exemplo, os recebimentos de novas mercadorias para galpões que estejam menos utilizados, ou que apresentem uma projeção menor.
Apesar de, à primeira vista, parecerem simples, as séries temporais podem ser alvo de análises sofisticadas, como a proposta pelo matemático Jean-Baptiste Joseph Fourier, conhecida como Transformada Discreta de Fourier:
que permite a identificação de padrões simétricos entre entradas sinusoidais, bastante usada em processamento de imagens e áudio, e até na descoberta de vida extra-terrestre (o projeto SETI - Search for Extra Terrestrial Inteligence, utiliza sua variação, chamada de FFT ou "Fast Fourier Transform" para busca de padrões nos sinais obtidos pelo observatório de Arecibo).
Redes Neurais também podem ser programadas para prever uma única saída a partir de uma série temporal.
A complexidade ou simplicidade de tal análise reside no objetivo desejado e metodologia adequada, não nos dados em si.
No caso de agrupamentos, TODOS os dados serão incluidos na análise, apresentando um único resultado.
Excluindo-se os efeitos caóticos (ver "Caos"), a maior dificuldade no uso de agrupamentos é a escolha de quais dados deverão compô-los, dado que não há uma única ferramenta, atualmente, capaz de indicar isso matematicamente.
Agrupamentos são mais úteis na criação de modelos de previsão de impacto, no qual diversos vetores são ponderados e alterações são inseridas metodologicamente, de forma a calcular os pontos e extensões de variação.
Programadas adequadamente (para evitar a "chuva por bateria - ver topo"), equações correlacionáis e redes neurais me parecem as melhores opções para o processamento destes grupos.
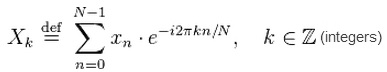

Uma série temporal ("time series") é um único vetor, ao qual se aplicam as técnicas de análise ou modelagem, para previsão de sua posição futura em t+n desejado.
A variação no uso de um único recurso, ou a somatória dos diversos indicadores de um mesmo KPI são bons exemplos disso.
Como o próprio nome diz, as séries temporais apresentam variância sobre tempo.
Agrupamentos
Um agrupamento é um conjunto de dados, selecionados do DW, sobre os quais se aplicam as análises ou modelagens COMO UM CONJUNTO.
Esta distinção é importante porque uma série temporal pode utilizar mais de um dado (como no exemplo de vários galpões), mas que representam a mesma análise, aplicada individualmente a cada um, e utilizada para comparações.
Aferição de Resultados
Probabilidade Bayesiana: Nível-p ("p-level"):


(Imagens e fórmulas obtidas da Wikipedia tm)
Uma vez criadas as análises e modelos, como aferir a precisão de seus resultados, uma vez que não há qualquer forma de se prever o futuro com absoluta segurança?
O ferramental estatístico responde a essa questão com, pelo menos, duas soluções: a avaliação por probabilidade Bayesiana e o chamado nível-p
Probabilidade Bayesiana
Sua definição é bastante simples: propõe-se um resultado, e se verifica se funcionou quando o dado real estiver disponível.
Este enunciado pode parecer sem sentido à primeira vista.
Mas se, por exemplo, uma serie temporal for considerada, podemos sempre mover o "presente" para algum ponto do "passado", no qual o resultado já é conhecido, e avaliar, em termos percentuais, a habilidade do modelo de calcular o valor futuro, como na avaliação de Real X Projetado, criado por uma rede neural (ao lado).
(Criado com Alyuda Excel tm)

Desta forma, um retrocesso metodológico no tempo pode nos fornecer a capacidade de previsão e, tão importante quanto, externar pontos ou combinações aos quais o modelo ou análise são mais sensíveis (gerando uma margem de erro maior).
Caso a margem de erro fique dentro de patamares aceitáveis, a análise ou modelo podem ser consideradas válidas.
Nível-p
É a porcentagem de probabilidade estatística de comprovação de uma hipótese nula.
Para se trabalhar com ele, criá-se a hipótese nula (seu resultado está errado), e a hipótese alternativa (seu resultado está certo). Depois verificá-se a probabilidade estatística (histórica), de sua previsão estar correta (ou, de a hipótese nula poder ser recusada).
No caso da imagem ao lado, a previsão (no alto, à direita), foi obtida por uma média simples da amostragem, e foram definidos como "aceitáveis", previsões que estejam a +/- 1xDP (Desvio-Padrão)
Para se calcular o nível-p, divide-se a quantidade de elementos históricos que estão "dentro" dos parâmetros aceitáveis, pela totalidade dos elementos considerados.
Mesmo que só visualmente, pode-se notar que os resultados para a análise ao lado não foram satisfatórios...

Produção ou Pesquisa

X

Apenas como conclusão deste ítem sobre "Análise", achei valido apontar a distinção entre análises voltadas à ambientes produtivos, e aquelas voltadas para pesquisas.
No caso de pesquisas, a criação, validação e obtenção dos resultados de uma análise já são um fim em si mesmas. As projeções serão utilizadas como base ou complemento de temas sob estudo, validando uma tése (por exemplo).
Já num ambiente produtivo, as análises e modelagens devem ser transformadas em serviços, sob uma área de operação, trabalhando 24/7, de forma a estarem sempre renovando seus resultados, reavaliando suas posições, e tomando ações quando determinados limites ("thresholds"), forem atingidos, e tomando ações como aumentando a monitoração sobre o ítem em questão (no caso de ser apenas um surto eventual), ou, no mínimo, avisando os gestores envolvidos no processo, sob cuja responsabilidade estes estudos se encontram.
Um tal ambiente produtivo replica as bases já conhecidas de outros sistemas informáticos, seguindo procedimentos para ativação das modelagens em produção, e sob o cuidado de operadores que se certifiquem que os processos estejam sendo executados de maneira correta e nos momentos esperados.